
I’m working on a new startup as I mentioned in my previous post, and as the technical co-founder, I am responsible for developing the first version of our product as a proof-of-concept or (ideally) as a functioning alpha/beta version that can be used with real customers to get feedback for our idea and business plan.
The basic architecture will be pretty standard: an iOS (and eventually Android) app, some backend services with a database, some integration with external/partner systems, and some limited web browser-based functionality. As a “greenfield” project, I have virtually no constraints with respect to how to build the solution, which programming languages to use, which cloud/deployment technology, etc.
In other words, I am the dog that finally caught up with the car that it had been chasing.

What do I do now??
I’m trying to be very disciplined about what decisions I’m making at this early stage, while at the same time trying not to put so much thought into things that I spend too much time trying to evaluate or justify a decision instead of just building something quickly that will work.
Here are a few different architecture/design/implementation decisions that I’m working on at the moment.
Deployment
Cloud deployments are all the fashion these days, and while I have some experience with public cloud providers, most of our deployments at my previous company used our own dedicated hardware in a hosted data center (IBM Softlayer), so our technical operations team had control over the entire stack. I think for my purposes, choosing one of the three major cloud providers (Microsoft, Google or Amazon) will make the most sense. But which one to choose and, for long term purposes, how to estimate cost? The services offered by the various cloud providers seem to be getting more sophisticated all the time. For example, who has heard of Amazon Quantum Ledger Database (QLDB), Amazon LumberYard, Amazon SageMaker? Most of these won’t be relevant for my application, but just wrapping your head around all of the offerings is daunting.
Backend Services
This should be the most straightforward part of the project for me, as I have a lot of experience here, and there are many mature frameworks for implementing web services. But there are some newer technologies to consider, such as Reactive Streams. The question of which programming language or environment to use is pretty crucial at this stage. I could do traditional Java web services with something like JAX-WS, or use a more popular Java-based framework such as Spring Boot for microservices. I could stay within the JVM ecosystem and use Scala or Kotlin or Clojure. (I attended a Kotlin meetup recently and the Ktor async web framework for Kotlin was discussed with some enthusiasm). Or I could venture into Node.JS territory and use TypeScript, thus allowing some synergy between potential front-end and back-end code to both leverage TypeScript. Or maybe write some services in Go. Rust, anyone??
I have no doubt that any one of these languages, along with an accompanying framework, could be used successfully for implementing some basic web services. For the business, my longer term concern is more focused on people: how easy will it be to hire people to work on this code in the future and what will they cost? There are certainly talented programmers/engineers working in pretty much every language/environment these days, but will it be easier to hire Java developers or Scala developers? TypeScript developers or Go developers? Or do I want to simply focus on hiring the most talented people regardless of background.
I’m reminded of this quote from Guido van Rossum, the creator of Python, from an earlier post:
Is there any characteristic that becomes fundamental to evaluate if we are looking for great Python programmers?
Guido: I’m afraid you are asking this from the perspective of the typical manager who simply wants to hire a bunch of Python programmers. I really don’t think there’s a simple answer, and in fact I think it’s probably the wrong question. You don’t want to hire Python programmers. You want to hire smart, creative, self-motivated people.
End User Application
Our application will eventually target both iOS and Android, but for our target market, iOS will make sense to target initially. This seems like the easiest decision then — just use Xcode with Swift 4, et voilà, we’ll have a decent iOS app. But when we eventually want an Android app, do we then develop one from scratch in Java or Kotlin?
How about one of the cross-platform frameworks? Multi-OS Engine (anyone ever heard of that), Xamarin, React Native, Flutter (which uses Dart language)? Or perhaps just implement some shared logic using Kotlin and sharing with iOS using Kotlin/Native?
Services/System Integration Architecture
At my previous company, our reliability/consistency paradigm for services such as payments was enforced primarily via our MySQL data store, along with some use of Redis for deduplicating requests. This had some advantages in that it was easy to understand the contract for how transactions would or would not be reliable (in our context-specific sense) by just examining the code. OK, maybe examining the code really is not so easy in many cases.
I ran across this post describing the differences between RabbitMQ (a traditional enterprise message queue) and Apache Kafka. I have been reading up on Apache Kafka and I know it’s becoming increasingly popular, and this article helped to elucidate some of the differences between Kafka and a traditional JMS-style message queueing solution.
I will post more here as I come to some decisions and implement some working code.
I’ve returned! After four years of silence here on Fun in Space, I’m going back to blogging. Let me catch you up with what’s been happening for me lately in the technium.
I left Clover in June, and have been mostly traveling and doing a variety of non-work related things since then. I’m working on a new startup of my own now (with a co-founder), so more on that later.
I’ll see if I can cover some of the highlights of what I worked on while at Clover.
- We launched 6 hardware products, and a mobile POS solution called Clover Go. The Clover Hub was a short-lived product (mentioned in passing in this GigaOm article) that combined a stock Android tablet (mostly ASUS TF300T) with a slightly customized Android operating system (it was based on CyanogenMod if memory serves). Our first fully integrated hardware product was called Clover Station (now replaced by Clover Station 2018). I helped to build an improved crash reporting system, and a new app for full service restaurants called ‘Tables’, built with my colleague Tamer. I also helped convert our Android build system to use Gradle, as I mentioned in a previous post.
- The next hardware products were the Clover Mobile (now discontinued) and Clover Mini. These products used the same internals in two different form factors. These devices were also much more complicated than the Clover Station from an engineering standpoint. We had to deliver a much more customized (Android) operating system, embedded code (based on FreeRTOS) that ran on a custom board using a Maxim 32550 secure microcontroller, and a whole suite of new user-facing and background applications. The core payment applications had to support both EMV and NFC standards, and I worked a lot on the payment subsystem in the embedded code, Android code, and web services that communicated with our payment processing partners.
- I helped launch Clover in United Kingdom and Republic of Ireland in early 2014, and later helped to lead the effort to bring Clover to Germany, Austria, and Argentina. (I also did some early work on Clover Canada project, but my colleagues did most of the work there). A lot of this work was in getting the devices certified with EMVCo Level 1 and Level 2 (I could write a whole series of articles on that), acquirer-level certification, and what we would call scheme certification (usually tests developed by MasterCard, Visa, American Express, Discover and other card scheme/associations).
- I published the first version of our Clover Android SDK to coincide with TechCrunch Disrupt SF Hackathon 2013. This SDK allows developers to build apps that will run on a Clover device and take advantage of the core services that we built to support the point-of-sale experience, including employee and customer management, order information, catalog and inventory management, and core payments.
- I built a team to deliver a new set of SDKs for integrating with Clover devices from an external system, including SDKs for Windows (built using C#/.NET), Android, iOS, Java, and Javascript. Booker was an early partner that my colleague Mike and I worked with who integrated with our Javascript/cloud offering.
- I led a project to integrate Clover with Google’s SmartTap functionality and presented the architecture at the New York Google Developer Group meetup. This was a fun project that was also demonstrated on-stage at Google I/O by my CEO John Beatty. This also was a predecessor to updating Clover to work with Apple NFC Value-Added Services (VAS).
- I did a lot of work to help scale our server infrastructure, mostly as team lead prioritizing the areas in which we introduced additional caching (via Redis, haproxy/nginx, memcached, Guava in-memory cache, etc.), optimized database queries, and updated our client architecture to more effectively distribute query load over time and prevent accidental spikes in requests that would overload the server.
Those are the highlights, I’m sure I’ll have some more topics from the Clover days to revisit in the future. My next post will cover some of the things that I’m researching while working on my new startup. It’s still a bit cloudy but, boy, when we get there…
OK, it’s been a while since I’ve posted anything here on Fun in Space, but now I have something interesting to show.
I experimented a bit with Apple’s new Swift programming language over the weekend and decided to try out accessing Clover’s web services (i.e. the stuff I work on during the day mostly) using Swift as a scripting language, more or less. Based on this tweet from Chris Lattner, I decided to try out a simple script for accessing point-of-sale order information via the Clover API.
I’m pleased to report that the the experiment was successful and I had fun doing it. The results are posted on Github here. A few notes:
- I’m quite amazed to see how much info there is on Swift already on the Internet. After being announced on Monday (6 days ago as of the time I’m writing this), virtually all of the questions I needed help answering were addressed in some way in either the documentation or the discussions on Stack Overflow and other places with respect to Swift.
- I like the static typing and type inference, but accessing JSON data via NSJSONSerialization was still a bit of a pain. If I were to develop a full-fledged Swift application, I’d probably use some type of data binding approach as we do in Java with the Clover Android SDK.
- I got a few hints from the Agent project, which provides a thin web request API on top of Swift. I chose to use NSURLSession instead of NSURLConnection that Agent uses, and this proved to be very straightforward.
- One part that was potentially quite tricky was that my script exited immediately before the NSURLSession tasks could be completed. I had to dig up some old information from my brain (with some help from Stack Overflow and this Gist) and put in a manual NSRunLoop to prevent the script from exiting until my tasks were completed.
- Passing in command line arguments to the script didn’t seem to work too well, so I relied on an environment variable (CLOVER_TOKEN) to pass in the authentication token to the script.
If anyone else accessing web services via Swift gives this a try and has any feedback, please let me know.
I attended Google’s Android Hackathon yesterday on the Google campus. The challenge for this hackathon was to build an Android app to generate memes. Because if there’s one thing the world needs more of, it is definitely meme-generating apps. OK, maybe not, but anyway, that was how the guidelines were presented. I originally wanted to do something interesting with communication between multiple devices. When I arrived at the hackathon, however, the battery on my Nexus 7 tablet was fully drained. I only had my ASUS TF300 tablet from work fully charged, but I didn’t have a USB cable for that in my backpack, so I figured I needed to get more creative.
My fallback idea was to do something related to natural language processing. This turned out to be a theme that a few of the hackathon winners pursued as well (spoiler alert: that list of winners did not include me). At first, I wondered if I could run one of the existing Java or Python-based NLP toolkits directly on Android. I have some experience with GATE, the General Architecture for Text Engineering developed at the University of Sheffield, Apache OpenNLP, and NLTK, a Python-based NLP library. In my fifteen or so minutes of research, I determined that getting any of these to run on Android would probably consume most of the time I had during the day, so I decided to stretch the hackathon rules a bit and develop a simple web service that my Android app could use. This turned out to be the bulk of the ‘interesting’ code that I wrote, which took about 1 hour, and of course the rest of the time (6 hours or so) I spent fiddling getting my Android UI to do something useful.
The web service I developed used JAX-RS and I decided to leverage the tools provided by IntelliJ IDEA to generate a simple skeleton web service for me using JAX-RS and Jersey. This was quite handy and I had a simple “hello world” web service running in less than a minute. I decided to resurrect some ideas that I’ve either been interested in or worked on in some capacity in previous projects, so I built a service that would extract a place name from a given URL. The basic idea is to run a document (URL) through an NLP toolkit and extract a list of place names. I then just performed a simple count and picked the place name that occurred most often in the document. The fancy name for this is geospatial named-entity recognition. I ended up using GATE, because it was the toolkit with which I was most familiar. GATE has a plugin called ANNIE (A Nearly-New Information Extraction system), which did most of the work. GATE/ANNIE uses primarily a rules-based approach to NLP, rather than statistical or machine-learning based NLP, which basically means that you don’t need to train the NLP engine with a large corpus of existing documents. The downside to the rules-based approach is that you end up needing to have rather sophisticated rulesets. Luckily, a good set of default rulesets for recognizing common entities like places, organizations, and locations is bundled with GATE/ANNIE. The only modification I made to the out-of-the-box ANNIE configuration was to include ‘Mountain View’ in the list of city names that it recognized by default.
So, the basic format for the service was to take a URL and return the place name that was referenced most often in the document. A simple test looked like this:
⚀ ~ $ curl "http://localhost:9998/memegen?url=http://en.wikipedia.org/wiki/France"
France
OK, so the basics of taking any given URL and extracting out a place name were taken care of. I then proceeded to build my Android app that would generate memes. Now, I will be the first to admit that generating Android UIs is not exactly my specialty. Nonetheless, I managed to come up with something that I thought looked halfway decent. The end result is not terribly useful, but then, I guess most meme generators aren’t really meant to be useful, they are just meant to entertain, right? For the memes themselves, I simply mapped a place name to a previously defined phrase to be used for that place.
Here is the default layout of my finished Android app:
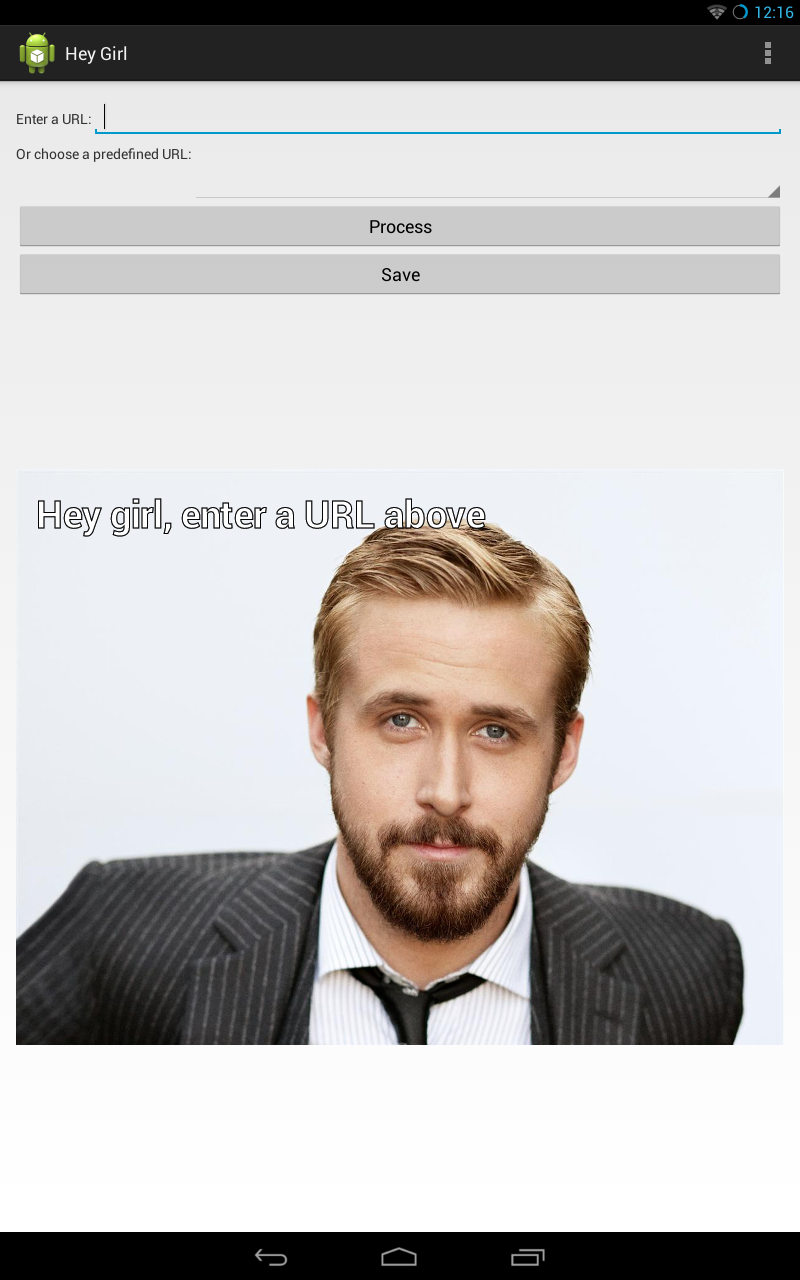
And here are the resulting memes, all copyrighted by yours truly.






If I didn’t already have a witty phrase associated with that place name:

And if no place name can be recognized:

I finally learned about zsh, thanks to a guy named Dietrich Featherston. It’s funny how some of the tools or habits we adopt can stay with us for so long and we often barely think about them. My shell of choice ‘back in the day’ (late 90s-ish) was usually tcsh. The choices we had back then seemed to be primarily Korn shell (ksh) and C shell (csh), of which tcsh was an enhanced version. Of course, you could use Bourne shell, aka the trusty /bin/sh, but it was far more primitive and few people aside from the communists at the Free Software Foundation (kidding) had heard of Bash (and consequently few people were aware just how bad the pun was that was used to inspire its name). So how did one decide which shell to use? Well, Korn shell had a slightly icky sounding name, so that was one strike against it. C shell sounded like it was more like C, and it’s true that csh scripts have a syntax that is closer to C. (Maybe C is to csh as Java is to Javascript?) In any case, csh and tcsh had a nifty feature called ‘file completion’ which meant you could hit the escape key and the name of the file or command would automatically be filled in for you on the command line. This was heady stuff, you guys. As far as I remember, this wasn’t a feature offered by ksh at the time and it certainly wasn’t present in most versions of Bourne shell (/bin/sh) that were installed on the various [Unixes/Unices/Unixen] to which I had access (SunOS, HP/UX, IBM AIX, SGI IRIX were the main ones that I recall). It turns out that the developer of tcsh borrowed this feature from the TENEX operating system built by Digital Equipment Corporation (DEC) and that’s where the ‘t’ in tcsh comes from. In fact, normal csh had the file completion feature but it was usually disabled by default, so you had to type ‘set filec’ to enable it. tcsh had file completion enabled by default, so it became easier to use it as a default whenever I had the choice. It also took me a long time to adapt to using tab as the file completion keystroke, though using tab does seem to make more sense now.
Anyway…. back to my current fun. I just installed zsh and also oh-my-zsh, which is pretty nifty stuff since I hadn’t given much thought to updating my shell in a long time. Most recently, I had updated my bash prompt (only using bash out of pure laziness since it’s the default on OS X) to show the current git branch when in a directory under revision control by Git. Very useful, but it turns out zsh and it’s associated plugins have this feature and many many more. It even has themes, a concept that would have been unheard of ‘back in the day’ when one rarely was connected to a shell or remote system that supported colors well.
So my one customization so far was to modify the default robbyrussell theme and replace the ➜ character with a randomly generated Unicode character that falls in the range between 9856 and 9861 in decimal. In other words, every new terminal window opened is a roll of the dice:
DIE=`echo "\\u"$((RANDOM%6+2680))`

I’ve been away from blogging for a while, but I promise I have a good excuse. Shortly after my last post at the end of April, I flew to California for a job interview, and shortly after that, I got a job offer, and shortly after that, I accepted and, well, you get the point.
I’m now working for a recent startup called Clover in Mountain View, CA and working on some pretty cool stuff. I’m sure I will be able to share some more details about our architecture over time.
In the meantime, here are a few things I’ve been working on or learning more about recently:
- Android Development – For all of the Apple computers and devices that I own, not to mention the incredible amount of money I’ve spent on the Apple/iTunes ecosystem, it seems a little surprising that I would end up working for a company for whom one of the main focuses is developing an Android-based platform for point-of-sale devices, but anyway, here I am. In the past week I developed my first simple Android app, mostly focusing on synchronization of data between back-end web services and Android’s local SQLite database.
- BoneCP – In attempting to track down an issue with long-running database connections being closed by our firewall, I developed some tests for the BoneCP connection pooling framework (see here). Nothing conclusive yet, but the behavior with regard to properly closing connections doesn’t seem quite right to me and the newest beta versions of BoneCP seem to behave even worse. I’ll write up a separate blog post on that later once I have some more definitive data.
- ANTLR – Starting to get up to speed on the ANTLR parser generator in hopes of using it for a combined web service testing and documentation framework. Overall goal is to automate both documenting and testing our web services so we don’t have multiple files to update when adding or changing part of our web service API. Also have been reading The Definitive ANTLR4 Reference and Language Implementation Patterns, both by Terence Parr, creator of ANTLR.
- Gradle – I’ve been reading more about Gradle this weekend, in part because the Android SDK is moving to Gradle, and of course, since IntelliJ IDEA now has good Gradle support, it is certainly worth checking out. My preliminary assessment is that it has a lot of promise and seems to represent a good evolution in a build tool leveraging the best practices from Ant+Ivy and Maven.
That’s it from me for now. Stay tuned for more updates from sunny California.
 I’ve recently been reading the book Masterminds of Programming, published by O’Reilly. This book contains interviews with the creators of seventeen historic and highly influential programming languages, including C++, Java, Haskell, Objective-C, Python, and many more.
I’ve recently been reading the book Masterminds of Programming, published by O’Reilly. This book contains interviews with the creators of seventeen historic and highly influential programming languages, including C++, Java, Haskell, Objective-C, Python, and many more.
I’m about halfway through the book and can highly recommend it. Here are a few good quotations that I have highlighted. (Interviewer questions are in bold.)
Bjarne Stroustrup, creator of C++:
How can we be sure that the advantages of OO are more valuable than the disadvantages? Maybe the problem that a good OO design is difficult to achieve is the root of all other problems.
Bjarne: <…> There is no one “root of all evil” in software development. Design is hard in many ways. People tend to underestimate the intellectual and practical difficulties involved in building a significant system involving software. It is not and will not be reduced to a simple mechanical “assembly line” process. Creativity, engineering principles, and evolutionary change are needed to create a satisfactory large system.
Guido van Rossum, creator of Python:
Is there any characteristic that becomes fundamental to evaluate if we are looking for great Python programmers?
Guido: I’m afraid you are asking this from the perspective of the typical manager who simply wants to hire a bunch of Python programmers. I really don’t think there’s a simple answer, and in fact I think it’s probably the wrong question. You don’t want to hire Python programmers. You want to hire smart, creative, self-motivated people.
James Gosling, creator of Java:
If it weren’t for Java, would Scala be your language of choice?
James: Yeah, probably.
Tom Love, co-creator of Objective-C, on hiring good programmers:
How do you hire a good programmer?
Tom: There’s a big topic. You might or might not know that my dissertation was a study on the psychological characteristics of successful programmers in the 1970s… There are actually some that are still alive. It’s quite amazing. There are certain cognitive psychological traits that you look for: memory ability, attention to detail. I also look for things like communication skills, both written and oral. Working in a team; it’s important that you be able to communicate effectively with the rest of the team and then it’s also important if you obtain leadership roles that you be able to communicate with customers or subject matter experts or other operations and maintenance teams that you need to interact with as you start to deploy products. I don’t make it a requirement, but I look for correlations like really excellent programmers, if I’m trying to hire somebody to be a chief designer and architect for a project. I’ll pay attention to their hobbies. If they’re very proficient in music, that’s a very good thing–proficient means has studied classical music and can perform a piano sonata from memory. That’s a pretty good test of their memory ability and attention to detail, and it should sound pretty good, too!
On a side note, I still require sheet music to perform a violin sonata, but I’m getting better.
Does productivity depend more on the quality of the programmer or the characteristics of the programming language?
Tom: The effect of individual differences will far outweigh any effect of the programming language. Studies from the 1970s show for programmers with the same educational background and same number of years’ experience, the number was 26:1 individual differences. I don’t think anybody claims that their programming language is 26 times better than somebody else’s.
Finally, there’s this exchange on the relative success of C++ versus Objective-C, which is priceless:
Why do you think that C++ was used more frequently than Objective-C?
Tom: It had the AT&T moniker behind it.
Just that?
Tom: I think so.
What do you think about Objective-C today?
Tom: It still exists. How about that?
Brad Cox, co-creator of Objective C, who may or may not have read my post on the “I, Pencil” essay, but has almost certainly studied some economics:
What do the lessons about the invention, further development, and adoption of your language say to people developing computer systems today and in the foreseeable future?
Brad: <…> I’ve used the common wooden pencil in some of my writing as an example. When I ask audiences which is “simpler”, a digital pencil like Microsoft Word or a wooden pencil, people agree the wooden variety is simpler. Until I point out that Microsoft Word was written by eight programmers, while the wooden variety involved thousands, none of whom could appreciate the full complexity of harvesting lumber, mining graphite, smelting metals, making lacquer, growing rapeseed for oil, etc. The complexity was there in the pencil, but hidden from the user.
In this passage, you hear echoes of Matt Ridley’s The Rational Optimist, and other economic texts such as The Wealth of Nations:
You’ve probably heard about the problems that the state of California recently had with their systems written in COBOL. Could having a system built with little bricks help us avoid the problem of legacy software in the future?
Brad: I believe very strongly in components, but I don’t want to oversell the idea—components don’t solve everything. Components are how people solve problems above a modest scale; it’s one thing that separates us from chimpanzees. We invented a way of solving problems by simply making it the other guy’s problem. It’s called specialization of labor, and it’s as simple as that. That’s how the humans differ from chimpanzees: they never invented that. They know how to make tools, they have a language, so for most of the obvious things there are no differences between chimps and humans. We discover how to solve problems by making it the other guy’s problem—through an economic system.
And finally, these insights comparing software ecosystems with the natural world:
Does your university background [in organic chemistry, mathematics and biology] influence your vision of software design?
Brad: Absolutely. Constantly.
If you examine ecological systems, you see software as an ecological system in all respects except that the system lacks anything like physical conservation laws—no conservation of mass or energy. The product of our labor is made of bits that can be copied so easily that it’s hard to buy, sell, and own them. The economic system, the ecology, breaks down.
If a leopard could replicate its food as we replicate software, there would be no improvement by either the leopard or its prey.
It’s a constant problem in software, how to own and be compensated for the products and for your efforts.
OK, I admit it. The biggest thing I knew about Node.js before working with it over the past couple of days was from this video, entitled: “Node.js is Bad Ass Rock Star Tech”.
It still cracks me up. However, after watching this intro video by the creator of Node.js and doing a few Google searches, I have a new (partial) web scraper written in Javascript (and using libraries from Node.js via the Node package manager) that is extremely simple. I’m pretty impressed. I should point out that I’m not trying to run any type of services here, just using Node.js as a scripting environment that I can run on the command line that allows me to use some simple Javascript and JQuery commands to do my web scraping. The code is simple enough that I could reproduce it here, pretty much verbatim (see also the original file in Github).
var $ = require('jquery');
var http = require('http');
var queenpediaSongList =
"http://queenpedia.com/index.php?title=Song_List";
var html = '';
http.get(queenpediaSongList, function(result) {
result.on('data', function(data) {
html += data;
}).on('end', function() {
var songitemsInTables =
$(html).find('#bodyContent > table')
.slice(1).find('td').find('li');
var songitemsInList =
$(html).find('#bodyContent > ul').find('li');
var songitems = $.merge(songitemsInTables, songitemsInList);
songitems.each(function() {
var songtitle = $(this).find('a').text().trim();
var songurl = $(this).find('a').attr('href');
console.log("Song Title = " + songtitle + ",
Song URL = " + songurl);
});
});
});
And there you have it. I should mention that a few of the search results I found for combining JQuery and Node.js seemed to be using some older techniques that might not strictly be necessary. I can’t really comment on those other posts as they might have had different needs than mine. I also can’t comment on whether Node.js is truly Bad Ass Rock Star Tech, but it does work well enough for the simple task that I gave it here.
I’ve posted some more code to Github for Project Miracle and now have at least one alternative to Python for web scraping. I decided to use Scala for my second attempt, partly because I want to get better at writing Scala code, and partly because I thought that support for using XML/XHTML would be superior on the JVM. This was true in a sense, but as with the Python code, things never seemed as straightforward as they should have been. I also got some more practice using SBT, which worked pretty well and was very easy to start using for a simple project.
To start with downloading the HTML, it’s as simple in Scala as one would like it to be:
val sb = new StringBuilder
for (line <- Source.fromURL(queenpediaSongList).getLines())
sb.append(line).append(Properties.lineSeparator)
val songListHTML = sb.toString()
I download the HTML first so that I can perform any necessary pre-processing before the parsing steps. As it turns out the Queenpedia Song List that I’ve been using as my test case has some malformed HTML, so I needed to clean that up before using an XML-based (or even strict HTML-based) parsing approach. I decided to try the JTidy project which is a port of HTML Tidy, which I had used in the Python code via PyTidyLib. The key word here, however, is port, which means that the behavior of the Java and the C libraries are not the same. It turns out that JTidy complains about a missing table summary or something like that, a feature mostly used for accessibility. The error message kindly suggests that I update the HTML document before running it through JTidy again. I thought that’s what you were supposed to be doing, JTidy!
A simple setting update to “force output” gets us past this step, but somewhere along the line, I was getting no results from the function call to clean up the original HTML. I experimented with using Tagsoup, an alternative library for cleaning up HTML, which seems to have a decent pedigree as it is used by Apache Tika. I wasn’t seeming to have any luck with that, so I switched back to JTidy and created a new Java project in IntelliJ IDEA to test things out, just in case I was running into some idiosyncrasies with the Scala environment. With this project, I eventually got the results I wanted from JTidy and could get back to parsing the HTML/XHTML content.
At the same time I was trying to figure out what was going wrong with cleaning up the HTML, I was trying to decide which XML approach/library to use in parsing out the song list. As I mentioned in a previous post, I had already figured out a single-line XPath statement that would extract the relevant links from the main song list page. It looked like this:
/html/body//div[@id="bodyContent"]/(table/tr/td/ul/li/a | ul/li/a)
Simple enough it seems. All I should need to do is instantiate some kind of XPathEvaluator object and evaluate this XPath statement against the cleaned up HTML string, et voilà. Right?
First, a note on the use of XML in Scala. Scala has built-in support for XML, but that package is relatively notorious for being outdated and “beyond fixing”. The project Anti-XML was started by Daniel Spiewak, who now works at Precog, as a clean-room replacement for Scala’s built-in XML support. The project looks promising but it looks like it hasn’t had any activity in over a year. The Scala Wiki contains information on other alternative XML libraries, the most promising of which seems to be Scales Xml. However, since I’m not familiar with any of these libraries, I decide to stay conservative and simply use the built-in Java XML libraries (i.e. JAXP). That seems like a low-risk approach.
Low-risk and low-functioning approach as it turns out. To test out the XML/XHTML interactively, I’ve been using the excellent <oXygen/> XML Editor, which has first-class support for XPath and XQuery, including XPath 2.0. Turns out I’ve been building XPath 2.0 expressions the whole time and Java’s built-in JAXP implementation does not support XPath 2.0. So I can either port my XPath statement back to be XPath 1.0 compliant or find a compatible XPath 2.0 library. After investigating XOM briefly (and wondering why I’d never really run across it in all my years of working with XML), I decide to go with Michael Kay’s wonderful Saxon library, which, for some unknown reason, appears to be one of the very few libraries actually implementing support for XPath 2.0 (and even XPath 3.0 in the commercial versions).

No, not that Saxon.
I briefly attempt to use Saxon via the normal JAXP XPath APIs. After getting no love from this approach after tinkering for a while, I decide to use Saxon’s native API called s9api. Using s9api, I initialize all of the required objects in 11 steps instead of 1, but I finally was able to extract the information I wanted from the HTML document.
Another interesting thing I learned while using the Saxon API was of a new feature in Scala 2.10 when converting between Java and Scala collections. The result of XPathSelector.evaluate() in s9api is an Iterable<XdmItem>. In order to use the standard Scala for/foreach loop, I needed to convert to a Scala Iterable. Normally, this can be done by importing scala.collection.JavaConversions._
In Scala 2.10.1 (maybe before, I’m not sure), you can be more explicit about the implicit conversions you want to enable, so I used the following import statements instead:
import scala.language.implicitConversions
import scala.collection.convert.WrapAsScala.iterableAsScalaIterable
The final result, though not complete (it doesn’t extract the lyrics from the individual song pages yet), is viewable in the current Github repository. Am I satisfied with the results? For now, using Scala was unnecessary, but also didn’t cause any extra problems. I think it’s safe to say I was using Scala as simply a “better Java” with some easier syntax and relaxed rules on when static types need to be declared. But truthfully, I wrote most of the code that ended up working in Java using IntelliJ IDEA first. IntelliJ automates so much for you, you never really have to worry about what types to declare.
Next step may be to try using Node.js, then I will proceed to try to do something interesting with the data I’ve acquired.
I spent this past weekend at an event called Startup Weekend. A friend of mine who runs the company KidReports told me about the event and convinced me to sign up. I wasn’t sure what to expect before I arrived, but the event turned out to be very enjoyable and I think I learned quite a lot. I’d consider participating in the next event in Colorado Springs or perhaps in Denver. If you haven’t heard of Startup Weekend, I encourage you to check out their main web site.
I won’t comment too much about the startup concept and team that I worked on for the moment in case it becomes The Next Big Thing, but I did get a chance to test out my Javascript and JQuery skills in helping to construct a somewhat working prototype for our app. Let me just say that my Javascript skills could use some sharpening. JQuery does make things pretty nice and easy, and I also utilized some JQueryUI widgets. I think I will spend some time reading my O’Reilly reference books on HTML, CSS, and Javascript so that I can become more self-sufficient in web front-end programming.
